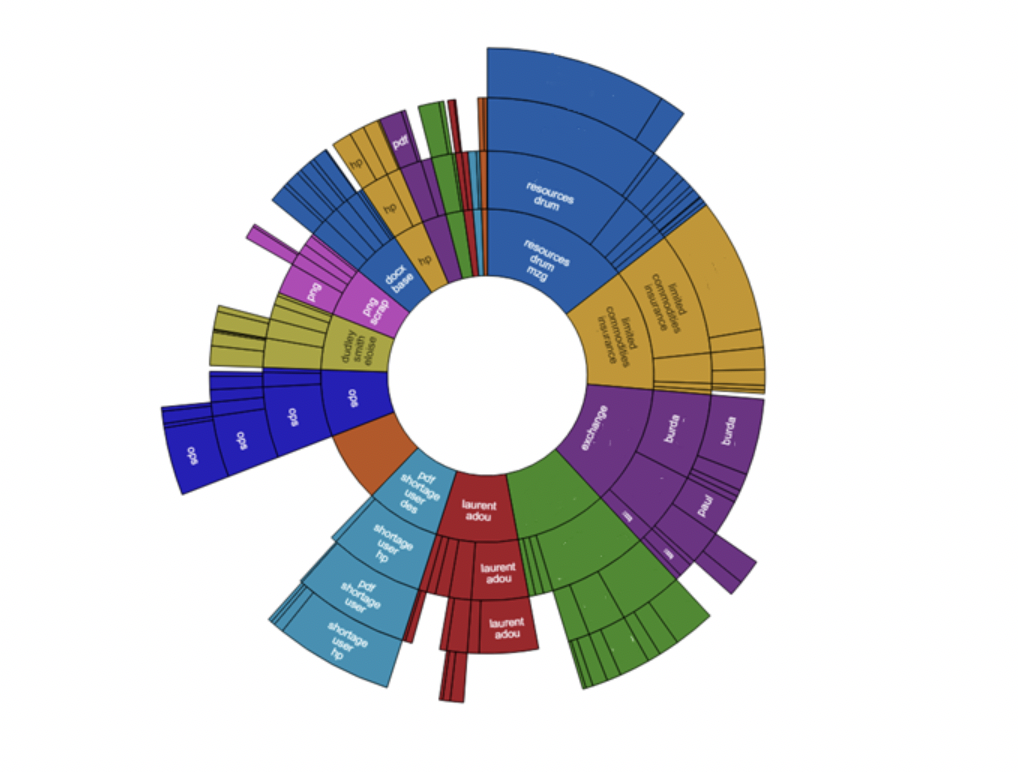
Clustering identifies documents which are conceptually similar to each other and divides them into smaller sub-sets of documents called clusters.
Another way to think of clustering is to imagine it as an act of sorting documents into boxes. Documents which discuss the same type of subjects are boxed together. These boxes are the clusters.
Clustering can be used to improve all stages of your review.
How Clustering Improves ECA:
Early Case Assessment (or ECA) refers to the process of the primary assessment of your data looking to pull out any immediately identifiable relevant files.
When working with an unfamiliar data set, clustering is a quick and efficient way of gaining a high-level overview of themes discussed within your collection of documents. A cluster is named by the top 10 terms that best represent it, so you can quickly identify key topics being discussed within your dataset. This can help determine clusters that contain both key documents and clusters likely to contain irrelevant material. This information can then assist with generating a list of search terms to target those key documents.
Clustering can improve keyword filtering by allowing you to identify synonyms of your predefined keywords that may not have been considered, and display documents which although not responsive to the explicit keywords are conceptually similar and as such may hold relevant information. Clustering identifies these related documents which may otherwise have been missed with just traditional keyword searching.
How Clustering Improves Review:
A single cluster of documents can be assigned to the same reviewer. Reviewing similar documents together can improve coding consistency and provide valuable context which can lead to more accurate coding.
Review can be prioritised to focus on the clusters which contain the most relevant concepts and help in identifying the key documents early on.
It is worth pointing out that this approach is likely to break the chronology of the review queue.



